
WHAT’S IN MY AI?
A Comprehensive Analysis of Datasets Used to
Train GPT-1, GPT-2, GPT-3, GPT-NeoX-20B,
Megatron-11B, MT-NLG, and Gopher
Alan D. Thompson
LifeArchitect.ai
March 2022
Rev 0

Contents
1. Overview 4
1.1. Wikipedia 6
1.2. Books 6
1.3. Journals 6
1.4. Reddit links 6
1.5. Common Crawl 6
1.6. Other 6
2. Common Datasets 6
2.1. Wikipedia (English) Analysis 7
2.2. Common Crawl Analysis 7
3. GPT-1 Dataset 8
3.1. GPT-1 Dataset Summary 9
4. GPT-2 Dataset 10
4.1. GPT-2 Dataset Summary 11
5. GPT-3 Datasets 12
5.1. GPT-3: Concerns with Dataset Analysis of Books1 and Books2 12
5.2. GPT-3: Books1 12
5.3. GPT-3: Books2 13
5.4. GPT-3 Dataset Summary 13
6. The Pile v1 (GPT-J & GPT-NeoX-20B) datasets 13
6.1. The Pile v1 Grouped Datasets 14
6.2. The Pile v1 Dataset Summary 15
7. Megatron-11B & RoBERTa Datasets 16
7.1. Megatron-11B & RoBERTa Dataset Summary 16
8. MT-NLG Datasets 17
8.1. Common Crawl in MT-NLG 17
8.2. MT-NLG Grouped Datasets 18
8.3. MT-NLG Dataset Summary 18
9. Gopher Datasets 19
9.1. MassiveWeb Dataset Analysis 19
9.2. Gopher: Concerns with Dataset Analysis of Wikipedia 20
9.3. Gopher: No WebText 20
9.4. Gopher Grouped Datasets 21
9.5. Gopher Dataset Summary 22
___________________
Alan D. Thompson. 2022. What’s in my AI? A Comprehensive Analysis of Datasets used to Train GPT…
https://LifeArchitect.ai/whats-in-my-ai 2

10. Conclusion 22
11. Further reading 23
Appendix A: Top 50 Resources: Wikipedia + CC + WebText (i.e. GPT-3) 25
About the Author
Dr Alan D. Thompson is an AI expert and consultant. With Leta (an AI powered by
GPT-3), Alan co-presented a seminar called ‘The new irrelevance of intelligence’ at
the World Gifted Conference in August 2021. His applied AI research and
visualizations are featured across major international media, including citations in the
University of Oxford’s debate on AI Ethics in December 2021. He has held positions
as chairman for Mensa International, consultant to GE and Warner Bros, and
memberships with the IEEE and IET.
To cite this article:
Thompson, A. D. (2022). What’s in my AI? A Comprehensive Analysis of Datasets
Used to Train GPT-1, GPT-2, GPT-3, GPT-NeoX-20B, Megatron-11B, MT-NLG, and
Gopher. https://LifeArchitect.ai/whats-in-my-ai
___________________
Alan D. Thompson. 2022. What’s in my AI? A Comprehensive Analysis of Datasets used to Train GPT…
https://LifeArchitect.ai/whats-in-my-ai 3
Abstract
Pre-trained transformer language models have become a stepping stone towards
artificial general intelligence (AGI), with some researchers reporting that AGI may
evolve
1
from our current language model technology. While these models are trained
on increasingly larger datasets, the documentation of basic metrics including dataset
size, dataset token count, and specific details of content is lacking. Notwithstanding
proposed standards
2
for documentation of dataset composition and collection, nearly
all major research labs have fallen behind in disclosing details of datasets used in
model training. The research synthesized here covers the period from 2018 to early
2022, and represents a comprehensive view of all datasets—including major
components Wikipedia and Common Crawl—of selected language models from GPT-1
to Gopher.
1. Overview
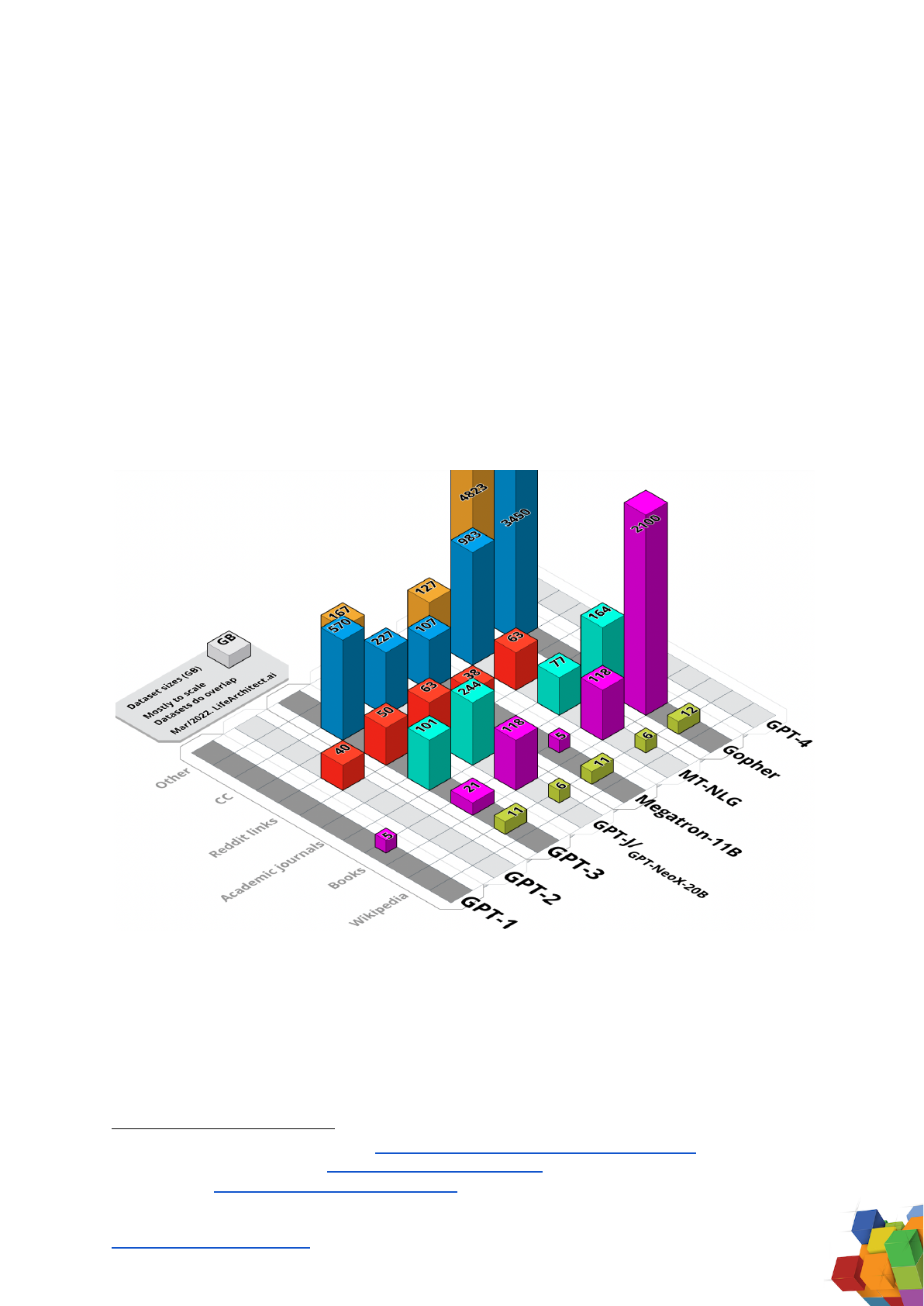
Figure 1. Visual Summary of Major Dataset Sizes. Unweighted sizes, in GB.
Since 2018, large language models have exploded in both development and
production use. Major research labs report incredibly high usage by the general
public. In March 2021, OpenAI announced
3
that its GPT-3 language model was being
used by “more than 300 applications [and generating] an average of 4.5 billion words
per day”. This is the equivalent of 3.1 million words per minute of new content,
3
OpenAI blog: https://openai.com/blog/gpt-3-apps/
2
Datasheet for Datasets paper: https://arxiv.org/abs/1803.09010
1
GPT-NeoX-20B paper: pp11, section 6 http://eaidata.bmk.sh/data/GPT_NeoX_20B.pdf
___________________
Alan D. Thompson. 2022. What’s in my AI? A Comprehensive Analysis of Datasets used to Train GPT…
https://LifeArchitect.ai/whats-in-my-ai 4

generated by just a single model. Notably, these language models are not even
completely understood, with Stanford researchers
4
recently admitting that “we
currently lack a clear understanding of how they work, when they fail, and what they
are even capable of due to their emergent properties”.
As new AI technology rapidly progresses, there has been a decline in documentation
quality about the datasets used to train these models. What is really inside my AI?
What is it made of? This article provides a comprehensive synthesis and analysis of
datasets used to train modern large language models.
Where primary model papers were opaque, the research synthesized here was
collected from secondary and tertiary sources, and often necessitated assumptions to
determine final estimates.
In this article, where the primary paper has been clear about a specific detail (for
example, token count or dataset size), it is considered ‘disclosed’, and marked in bold.
In many cases, it is necessary to include assumptions to determine final estimates,
referencing secondary and tertiary sources where appropriate. In these instances, the
detail (for example, token count or dataset size) is considered ‘determined’, and
marked in italics.
For each model, datasets are categorized into six groups: Wikipedia, Books, Journals,
Reddit links, Common Crawl, and Other.
Wikipedia
Books
Journals
Reddit
links
CC
Other
Total
GPT-1
4.6
4.6
GPT-2
40
40
GPT-3
11.4
21
101
50
570
753
The Pile v1
6
118
244
63
227
167
825
Megatron-11B
11.4
4.6
38
107
161
MT-NLG
6.4
118
77
63
983
127
1374
Gopher
12.5
2100
164.4
3450
4823
10550
Table 1. Summary of Major Dataset Sizes. Shown in GB. Disclosed in bold.
Determined in italics. Raw training dataset sizes only.
4
On the Opportunities and Risks of Foundation Models: https://arxiv.org/abs/2108.07258
___________________
Alan D. Thompson. 2022. What’s in my AI? A Comprehensive Analysis of Datasets used to Train GPT…
https://LifeArchitect.ai/whats-in-my-ai 5

1.1. Wikipedia
Wikipedia is a free, multilingual, collaborative, online encyclopedia written and
maintained by a community of over 300,000 volunteers. As of April 2022, there are
over 6.4 million articles in the English Wikipedia, containing over 4 billion words
5
. The
text is valuable as it is rigorously referenced, written in expository prose, and spans
many languages and domains. Generally, an English-only filtered version of Wikipedia
is a popular starting point for use as a dataset by major research labs.
1.2. Books
Narratives consisting of a mix of fiction and nonfiction books are useful for coherent
storytelling and responses. Includes datasets like Project Gutenberg and Smashwords
(Toronto BookCorpus/BookCorpus).
1.3. Journals
Papers in preprint and published journals provide a solid and rigorous foundation for
datasets, as academic writing typically demonstrates methodical, rational, and
meticulous output. Includes datasets like ArXiv and The National Institutes of Health
(US).
1.4. Reddit links
WebText is a large dataset sourced from a general web scrape of all outbound links
from social media platform Reddit, where the links have received at least 3 upvotes.
This is used as a heuristic indicator for popular content, perhaps suggesting higher
quality links and subsequent text data.
1.5. Common Crawl
Common Crawl is a large dataset of website crawls from 2008-present, including raw
web pages, metadata, and text extracts. Common Crawl includes text from diverse
languages and domains. An English-only filtered version of Common Crawl called C4
is a popular starting point for use as a dataset by major research labs.
1.6. Other
Datasets which do not fit into any of the groups above include code datasets like
GitHub, conversation forums like StackExchange, and video subtitle datasets.
2. Common Datasets
Since 2019, most transformer-based large language models (LLMs) rely on large
datasets from English Wikipedia, and from the Common Crawl. In this section, we
provide a high-level overview of English Wikipedia by category, and the top domains
in Common Crawl using Google C4
6
(Colossal Clean Crawled Corpus) based on the
6
C4 dataset: https://www.tensorflow.org/datasets/catalog/c4
5
Size of Wikipedia: https://en.wikipedia.org/wiki/Wikipedia:Size_of_Wikipedia
___________________
Alan D. Thompson. 2022. What’s in my AI? A Comprehensive Analysis of Datasets used to Train GPT…
https://LifeArchitect.ai/whats-in-my-ai 6

Common Crawl dataset
7
, with reference to the comprehensive analysis conducted by
Jesse Dodge and team at AllenAI (AI2)
8
.
2.1. Wikipedia (English) Analysis
Detail on Wikipedia by category
9
is included below, with coverage of 1001 random
articles sampled in 2015, with researchers noting the stability of spread over time.
Assuming an 11.4GB cleaned and filtered version of English Wikipedia with 3 billion
tokens, we can determine category sizes and tokens.
Rank
Category
Percentage
Size (GB)
Tokens (M)
1
2
3
4
5
6
7
8
9
10
Biography
Geography
Culture and Arts
History
Biology, Health, and Medicine
Sports
Business
Other society
Science & Math
Education
27.8%
17.7%
15.8%
9.9%
7.8%
6.5%
4.8%
4.4%
3.5%
1.8%
3.1
1.9
1.7
1.1
0.9
0.7
0.5
0.5
0.4
0.2
834
531
474
297
234
195
144
132
105
54
Total
100%
11.4
3000
Table 2. English Wikipedia Dataset Categories. Disclosed in bold. Determined in
italics.
2.2. Common Crawl Analysis
Based on work in the C4 paper by AllenAI (AI2), we can determine both token count
and overall percentage of each domain for the filtered English C4 dataset, which is
305GB with 156B tokens.
Rank
Domain
Tokens
(M)
%
Rank
Domain
Tokens
(M)
%
1
2
Google Patents
The NY Times
750
100
0.48%
0.06%
13
14
Frontiers Media
Business Insider
60
60
0.04%
0.04%
9
Wikipedia categories: https://en.wikipedia.org/wiki/User:Smallbones/1000_random_results: “What
topics does Wikipedia cover? Has the coverage changed over time? These and similar questions are
examined using 1001 random articles sampled in December, 2015… These proportions are fairly stable
over time… Biography (27.8%) Geography (17.7%) Culture and arts (15.8%) History (9.9%) Biology, health,
and medicine (7.8%) Sports (6.5%) Business (4.8%) Other society (4.4%) Science & Math (3.5%) Education
(1.8%)”
8
C4 paper: https://arxiv.org/abs/2104.08758 pp2, Figure 1 right
7
Common Crawl website: https://commoncrawl.org/
___________________
Alan D. Thompson. 2022. What’s in my AI? A Comprehensive Analysis of Datasets used to Train GPT…
https://LifeArchitect.ai/whats-in-my-ai 7

Rank
Domain
Tokens
(M)
%
Rank
Domain
Tokens
(M)
%
3
4
5
6
7
8
9
10
11
12
Los Angeles Times
The Guardian
PLoS
Forbes
HuffingtonPost
Patents.com
Scribd
Washington Post
The Motley Fool
IPFS
90
90
90
80
75
71
70
65
61
60
0.06%
0.06%
0.06%
0.05%
0.05%
0.05%
0.04%
0.04%
0.04%
0.04%
15
16
17
18
19
20
21
22
23
Chicago Tribune
Booking.com
The Atlantic
Springer Link
Al Jazeera
Kickstarter
FindLaw Caselaw
NCBI
NPR
59
58
57
56
55
54
53
53
52
0.04%
0.04%
0.04%
0.04%
0.04%
0.03%
0.03%
0.03%
0.03%
Total
Remainder
2.2B
153.8B
1.42%
98.58%
Table 3. C4: Top 23 Domains (excluding Wikipedia). Disclosed in bold. Determined
in italics.
3. GPT-1 Dataset
The GPT-1 model was released by OpenAI in 2018, with 117M parameters. The paper
was unclear about the source and contents of the training dataset used
10
. The paper
misspelled ‘BookCorpus’ as ‘BooksCorpus’. BookCorpus is based on free books
written by unpublished authors and sourced from Smashwords, an ebook website that
describes itself as “the world’s largest distributor of indie ebooks”. The dataset has
also been called the Toronto BookCorpus. Several recreations of the BookCorpus
determined the size of that dataset to be 4.6GB
11
.
In 2021, a comprehensive retrospective analysis was conducted on the BookCorpus
dataset
12
. Corrections were provided for genre grouping and book counts by genre.
Further detail on book genres inside the dataset includes:
Count
Genre
Book count
Percentage
(Book count / 11038)
1
2
3
4
5
6
7
8
Romance
Fantasy
Science Fiction
New Adult
Young Adult
Thriller
Mystery
Vampires
2880
1502
823
766
748
646
621
600
26.1%
13.6%
7.5%
6.9%
6.8%
5.9%
5.6%
5.4%
12
BookCorpus Retrospective Datasheet paper: pp9 https://arxiv.org/abs/2105.05241
11
https://huggingface.co/datasets/bookcorpus: “Size of the generated dataset: 4629.00 MB”
10
GPT-1 paper: pp4 “We use the BooksCorpus dataset for training the language model.”
___________________
Alan D. Thompson. 2022. What’s in my AI? A Comprehensive Analysis of Datasets used to Train GPT…
https://LifeArchitect.ai/whats-in-my-ai 8
Count
Genre
Book count
Percentage
(Book count / 11038)
9
10
11
12
13
14
15
16
Horror
Teen
Adventure
Other
Literature
Humor
Historical
Themes
448
430
390
360
330
265
178
51
4.1%
3.9%
3.5%
3.3%
3.0%
2.4%
1.6%
0.5%
Total
11038
100%
Table 4. BookCorpus Genres. Disclosed in bold. Determined in italics.
In subsequent dataset recreations (i.e. for The Pile v1 and others), further filtering was
applied to: exclude the ‘Vampires’ genre, decrease the percentage of books in the
‘Romance’ genre, increase the percentage of books in the ‘Historical’ genre,
substantially increase the number of books collected.
3.1. GPT-1 Dataset Summary
The final dataset summary analysis of the GPT-1 model is:
Wikipedia
Books
Journals
Reddit links
CC
Other
Total
GB
4.6
4.6
Tokens
1.3
1.3
Table 5. GPT-1 Datasets Summary. Shown in GB. Disclosed in bold. Determined in
italics.
___________________
Alan D. Thompson. 2022. What’s in my AI? A Comprehensive Analysis of Datasets used to Train GPT…
https://LifeArchitect.ai/whats-in-my-ai 9

4. GPT-2 Dataset
The GPT-2 model was released by OpenAI in 2019, with 1.5B parameters. The GPT-2
paper was clear about the size
13
of the training dataset used, but not about the
contents. The GPT-2 model card
14
(in the GPT-2 GitHub repository) was clear about
the model contents.
Token count can be derived from the GPT-3 paper, which uses an extended version of
WebText for 19B tokens. It has been assumed that this 2020 extended version has 12
months of additional data, and so it is possible that it is around 25% larger than the
2019 GPT-2 version
15
. The GPT-2 final token count is determined to be around 15B.
Detail on the contents of WebText as a percentage of the dataset can be determined
assuming that the model card is showing count of links, each of which can be divided
by the total of 45 million links, as noted in the GPT-2 paper.
The determined token count of 15B can then be used to find a token count per
domain. Note that of the Top 1,000 domains available, only the Top 50 domains are
shown here.
Rank
Domain
Links
(M)
%
Tokens
(M)
Rank
Domain
Links
(M)
%
Tokens
(M)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Google
Archive
Blogspot
GitHub
The NY Times
WordPress
WashingtonPost
Wikia
BBC
TheGuardian
eBay
Pastebin
CNN
Yahoo
HuffingtonPost
1.54
0.60
0.46
0.41
0.33
0.32
0.32
0.31
0.31
0.25
0.21
0.21
0.20
0.20
0.19
3.4%
1.3%
1.0%
0.9%
0.7%
0.7%
0.7%
0.7%
0.7%
0.5%
0.5%
0.5%
0.4%
0.4%
0.4%
514
199
152
138
111
107
105
104
104
82
70
70
66
65
62
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
Independent
Etsy
Craigslist
BusinessInsider
Telegraph
Wizards
USAtoday
TheHill
NHL
FoxNews
Taobao
Bloomberg
NPR
MLB
LA Times
0.11
0.11
0.10
0.09
0.09
0.09
0.08
0.08
0.08
0.08
0.08
0.08
0.08
0.08
0.08
0.2%
0.2%
0.2%
0.2%
0.2%
0.2%
0.2%
0.2%
0.2%
0.2%
0.2%
0.2%
0.2%
0.2%
0.2%
35
35
33
31
31
30
28
27
27
26
26
26
26
26
26
15
GPT-3 paper: “WebText2: 19 billion tokens. [Alan: WebText2 is slightly extended from WebText, so we
can subtract 20% to get 15 billion]”
14
GPT-2 model card: https://github.com/openai/gpt-2/blob/master/model_card.md: “We’ve published a
list of the top 1,000 domains present in WebText and their frequency. The top 15 domains by volume in
WebText are: Google, Archive, Blogspot, GitHub, NYTimes, Wordpress, Washington Post, Wikia, BBC,
The Guardian, eBay, Pastebin, CNN, Yahoo!, and the Huffington Post.”
13
GPT-2 paper: pp3 “we scraped all outbound links from Reddit, a social media platform, which
received at least 3 karma. This can be thought of as a heuristic indicator for whether other users found
the link interesting, educational, or just funny….WebText, contains the text subset of these 45 million
links… which does not include links created after Dec 2017 and which after de-duplication and some
heuristic based cleaning contains slightly over 8 million documents for a total of 40 GB of text. We
removed all Wikipedia documents from WebText…”
___________________
Alan D. Thompson. 2022. What’s in my AI? A Comprehensive Analysis of Datasets used to Train GPT…
https://LifeArchitect.ai/whats-in-my-ai 10
Rank
Domain
Links
(M)
%
Tokens
(M)
Rank
Domain
Links
(M)
%
Tokens
(M)
16
17
18
19
20
21
22
23
24
25
Go
Reuters
IMDb
Goo
NIH
CBC
Apple
Medium
DailyMail
SteamPowered
0.19
0.18
0.18
0.16
0.14
0.14
0.13
0.13
0.12
0.11
0.4%
0.4%
0.4%
0.4%
0.3%
0.3%
0.3%
0.3%
0.3%
0.2%
62
61
61
54
47
45
43
42
40
36
41
42
43
44
45
46
47
48
49
50
Megalodon
ESPN
KickStarter
BreitBart
ABC
NewEgg
WWE
MyAnimeList
Microsoft
Buzzfeed
0.08
0.07
0.07
0.07
0.07
0.07
0.07
0.07
0.07
0.06
0.2%
0.2%
0.2%
0.2%
0.2%
0.2%
0.1%
0.1%
0.1%
0.1%
25
24
24
24
23
23
22
22
22
22
Total
Remainder
9.3M
35.7
20.7%
79.3%
Table 6. WebText: Top 50 Domains. Disclosed in bold. Determined in italics.
4.1. GPT-2 Dataset Summary
The final dataset summary analysis of the GPT-2 model is:
Wikipedia
Books
Journals
Reddit links
CC
Other
Total
GB
40
40
Tokens
15
15
Table 7. GPT-2 Datasets Summary. Disclosed in bold. Determined in italics.
___________________
Alan D. Thompson. 2022. What’s in my AI? A Comprehensive Analysis of Datasets used to Train GPT…
https://LifeArchitect.ai/whats-in-my-ai 11

5. GPT-3 Datasets
The GPT-3 model was released by OpenAI in 2020, with 175B parameters. The paper
was clear about the token counts
16
of the training datasets used, but the contents and
sizes were unclear (except for the size of Common Crawl
17
).
Dataset
Tokens
(billion)
Assumptions
Tokens per byte
(Tokens / bytes)
Ratio
Size
(GB)
Common Crawl (filtered)
WebText2
Books1
Books2
Wikipedia
410B
19B
12B
55B
3B
-
25% > WebText
Gutenberg
Bibliotik
See RoBERTa
0.71
0.38
0.57
0.54
0.26
1:1.9
1:2.6
1:1.75
1:1.84
1:3.8
570
50
21
101
11.4
Total
499B
753.4GB
Table 8. GPT-3 Datasets. Disclosed in bold. Determined in italics.
5.1. GPT-3: Concerns with Dataset Analysis of Books1 and Books2
Of particular concern, sizes and sources for datasets Books1 (12B tokens) and Books2
(55B tokens) were not disclosed by OpenAI in the GPT-3 paper. Several hypotheses
have been put forward about the sources of these two datasets, including similar
datasets from LibGen
18
and Sci-Hub, both of which are too large to match, having
datasets measured in many Terabytes.
5.2. GPT-3: Books1
The GPT-3 Books1 dataset cannot be the same as the GPT-1 BookCorpus, due to the
Books1 dataset’s noted larger size of 12 billion tokens. The GPT-1 BookCorpus was
described in a cited paper
19
as having 984.8M words, which may be equivalent to only
1.3B tokens (984.8 words x 1.3 word to token multiplier).
19
BookCorpus paper: https://arxiv.org/abs/1506.06724: “# of words: 984,846,357 [Alan: BookCorpus is
then 1.3B tokens. We want 12-55B tokens]”
18
BookCorpus repo: https://github.com/soskek/bookcorpus/issues/27: “books3.tar.gz seems to be
similar to OpenAI's mysterious "books2" dataset referenced in their papers. Unfortunately OpenAI will
not give details, so we know very little about any differences. People suspect it's "all of libgen", but it's
purely conjecture. Nonetheless, books3 is "all of bibliotik"...”
17
GPT-3 paper: pp8 “we added several curated high-quality datasets, including an expanded version of
the WebText dataset, collected by scraping links over a longer period of time, and first described in, two
internet-based books corpora (Books1 and Books2) and English-language Wikipedia… The
CommonCrawl data was downloaded from 41 shards of monthly CommonCrawl covering 2016 to 2019,
constituting 45TB of compressed plaintext before filtering and 570GB after filtering, roughly equivalent
to 400 billion byte-pair-encoded tokens”
16
GPT-2 paper: pp3 “GPT-3: pp9, Table 2.2 “CC: 410B tokens. WebText2: 19B tokens. Books1: 12B
tokens. Books2: 55B tokens. Wiki: 3B tokens”
___________________
Alan D. Thompson. 2022. What’s in my AI? A Comprehensive Analysis of Datasets used to Train GPT…
https://LifeArchitect.ai/whats-in-my-ai 12
It is possible that Books1 aligns with Gutenberg via the Standardized Project
Gutenberg Corpus (SPGC), an open science approach to a curated version of the
complete PG data of the Gutenberg Project. The SPGC is 12 billion tokens
20
, and
about 21GB
21
.
5.3. GPT-3: Books2
It is possible that Books2 (55B tokens) aligns with Bibliotik, and a dataset made up of
data from this source was collected by EleutherAI as part of The Pile v1. That version
of Bibliotik is 100.96GB
22
, which gives a determined count of only 25B tokens; lower
than the 55B tokens disclosed for Books2. However, using the ‘tokens per byte’ ratio
of SPGC (around 1:1.75), the Bibliotik token count and size would more closely match
that of Books2.
5.4. GPT-3 Dataset Summary
A list of top resources for datasets using Wikipedia + CommonCrawl + WebText is
outlined in Appendix A. The final dataset summary analysis of the GPT-3 model is:
Wikipedia
Books
Journals
Reddit links
CC
Other
Total
GB
11.4
21
101
50
570
753
Tokens
3
12
55
19
410
499
Table 9. GPT-3 Datasets Summary. Disclosed in bold. Determined in italics.
6. The Pile v1 (GPT-J & GPT-NeoX-20B) datasets
The Pile v1 dataset was released by EleutherAI in 2021, and the dataset has been
used to train many models including GPT-J, GPT-NeoX-20B, and as a partial dataset
for other models including MT-NLG. The Pile v1 paper was very clear about the
sources and sizes of the training datasets used. With the addition of token counts,
The Pile v1 paper should be used as the gold standard for future documentation of
datasets.
Further detail on the token counts can be determined using information made
available in the paper, Tables 1 (size in GB) and 7 (Tokens per byte)
23
.
23
The Pile v1 paper: pp3, Table 1 for datasets. pp28, Table 7 for Tokens per byte.
22
The Pile v1 paper: “Books3 (Bibliotik tracker): 100.96GB” [Alan: multiplied by Tokens per byte of
0.2477 = 25B tokens]
21
Gutenberg repo: https://zenodo.org/record/2422561 “uncompressed size: 3GB (counts) + 18GB
(tokens) [21GB total]”
20
Gutenberg paper: https://arxiv.org/abs/1812.08092: “we present the Standardized Project Gutenberg
Corpus (SPGC), an open science approach to a curated version of the complete PG data containing
more than 50,000 books and more than 3×109 word-tokens [Alan: equivalent to about 12B BPE tokens,
see below]”
___________________
Alan D. Thompson. 2022. What’s in my AI? A Comprehensive Analysis of Datasets used to Train GPT…
https://LifeArchitect.ai/whats-in-my-ai 13

Count
Dataset
Raw Size
(GB)
Tokens per byte
(Tokens / bytes)
Tokens
(Raw Size x TpB)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
Common Crawl (Pile-CC)
PubMed Central
Books3
OpenWebText2
ArXiv
Github
FreeLaw
Stack Exchange
USPTO Background
PubMed Abstracts
Gutenberg
OpenSubtitles
Wikipedia
DM Mathematics
Ubuntu IRC
BookCorpus2
EuroParl
HackerNews
YouTubeSubtitles
PhilPapers
NIH ExPorter
Enron Emails
227.12
90.27
100.96
62.77
56.21
95.16
51.15
32.20
22.90
19.26
10.88
12.98
6.38
7.75
5.52
6.30
4.59
3.90
3.73
2.38
1.89
0.88
0.2291
0.3103
0.2477
0.2434
0.3532
0.4412
0.2622
0.3436
0.2116
0.2183
0.2677
0.2765
0.2373
0.8137
0.3651
0.2430
0.3879
0.2627
0.4349
0.2688
0.1987
0.3103
52.0B
28.0B
25.0B
15.3B
19.9B
42.0B
13.4B
11.1B
4.8B
4.2B
2.9B
3.6B
1.5B
6.3B
2.0B
1.5B
1.8B
1.0B
1.6B
0.6B
0.4B
0.3B
Total
825.18GB
239.2B
Table 10. The Pile v1 Dataset. Disclosed in bold. Determined in italics.
6.1. The Pile v1 Grouped Datasets
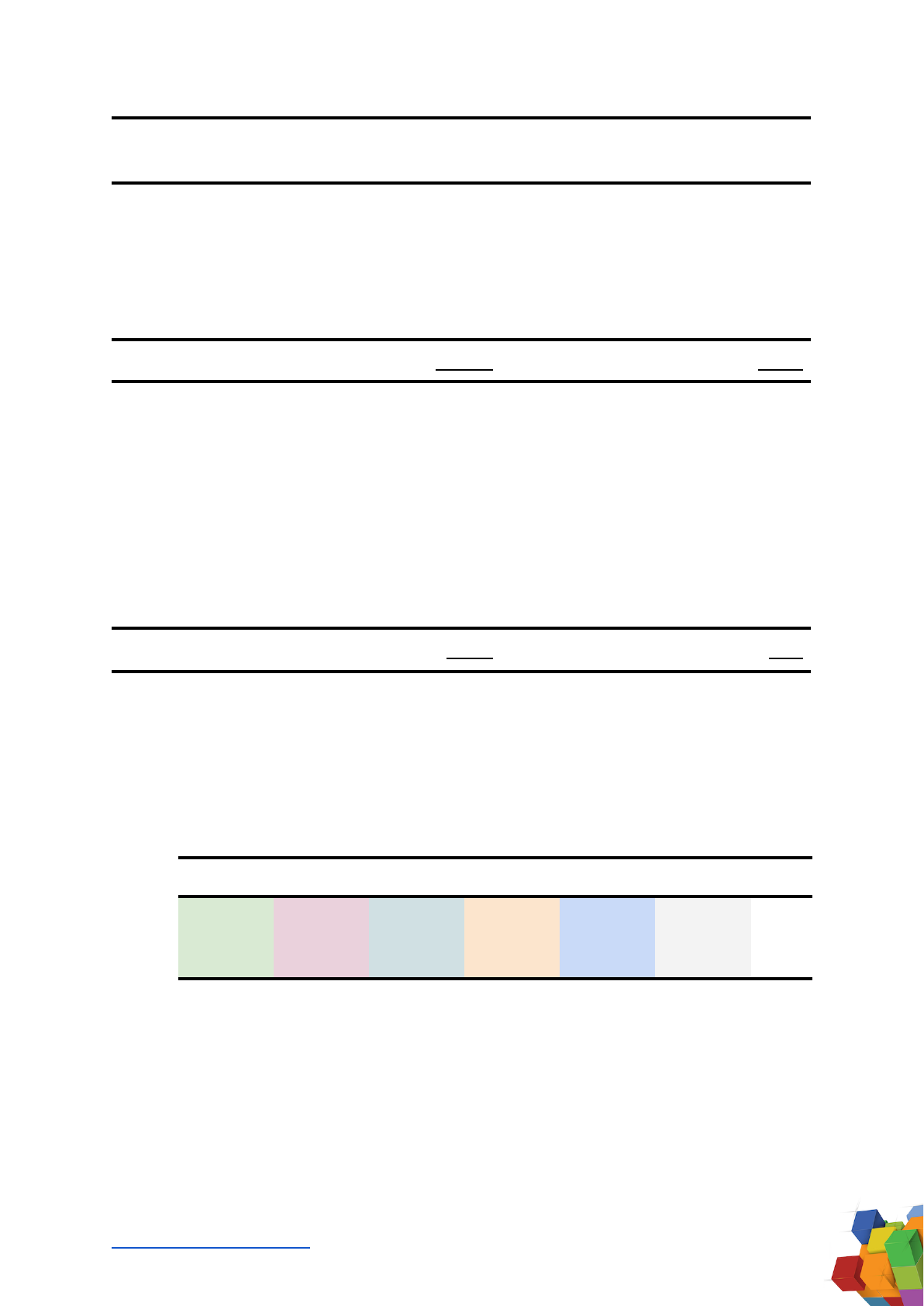
To determine dataset sizes for categories like ‘Books’, ‘Journals’, and ‘CC’, datasets
have been grouped according to component, as shown in the table below.
Count
Dataset
Raw Size
(GB)
Tokens per byte
(Tokens / bytes)
Tokens
(Raw Size x TpB)
1
2
3
Books
Books3
Gutenberg
BookCorpus2
100.96
10.88
6.30
0.3103
0.2677
0.2430
28.0B
2.9B
1.5B
Books total
118.14
32.4
4
Journals
PubMed Central
90.27
0.3103
28.0B
___________________
Alan D. Thompson. 2022. What’s in my AI? A Comprehensive Analysis of Datasets used to Train GPT…
https://LifeArchitect.ai/whats-in-my-ai 14
Count
Dataset
Raw Size
(GB)
Tokens per byte
(Tokens / bytes)
Tokens
(Raw Size x TpB)
5
6
7
8
9
10
ArXiv
FreeLaw
USPTO Background
PubMed Abstracts
PhilPapers
NIH ExPorter
56.21
51.15
22.90
19.26
2.38
1.89
0.3532
0.2622
0.3436
0.2183
0.2688
0.1987
19.9B
13.4B
11.1B
4.2B
0.6B
0.4B
Journals total
244.06
77.6B
11
12
13
14
15
16
17
18
19
Other
Github
Stack Exchange
OpenSubtitles
DM Mathematics
Ubuntu IRC
EuroParl
HackerNews
YouTubeSubtitles
Enron Emails
95.16
32.20
12.98
7.75
5.52
4.59
3.90
3.73
0.88
0.4412
0.3436
0.2765
0.8137
0.3651
0.3879
0.2627
0.4349
0.3103
42.0B
11.1B
3.6B
6.3B
2.0B
1.8B
1.0B
1.6B
0.3B
Other total
166.71
69.7
Table 11. The Pile v1 Grouped Datasets (excluding Wikipedia, CC, and WebText).
Disclosed in bold. Determined in italics.
6.2. The Pile v1 Dataset Summary
The final dataset summary analysis of the Pile v1 dataset and GPT-J and
GPT-NeoX-20B models is:
Wikipedia
Books
Journals
Reddit links
CC
Other
Total
GB
6
118
244
63
227
167
825
Tokens
1.4
32
77
15
52
70
247
Table 12. The Pile v1 Datasets Summary. Disclosed in bold. Determined in italics.
___________________
Alan D. Thompson. 2022. What’s in my AI? A Comprehensive Analysis of Datasets used to Train GPT…
https://LifeArchitect.ai/whats-in-my-ai 15
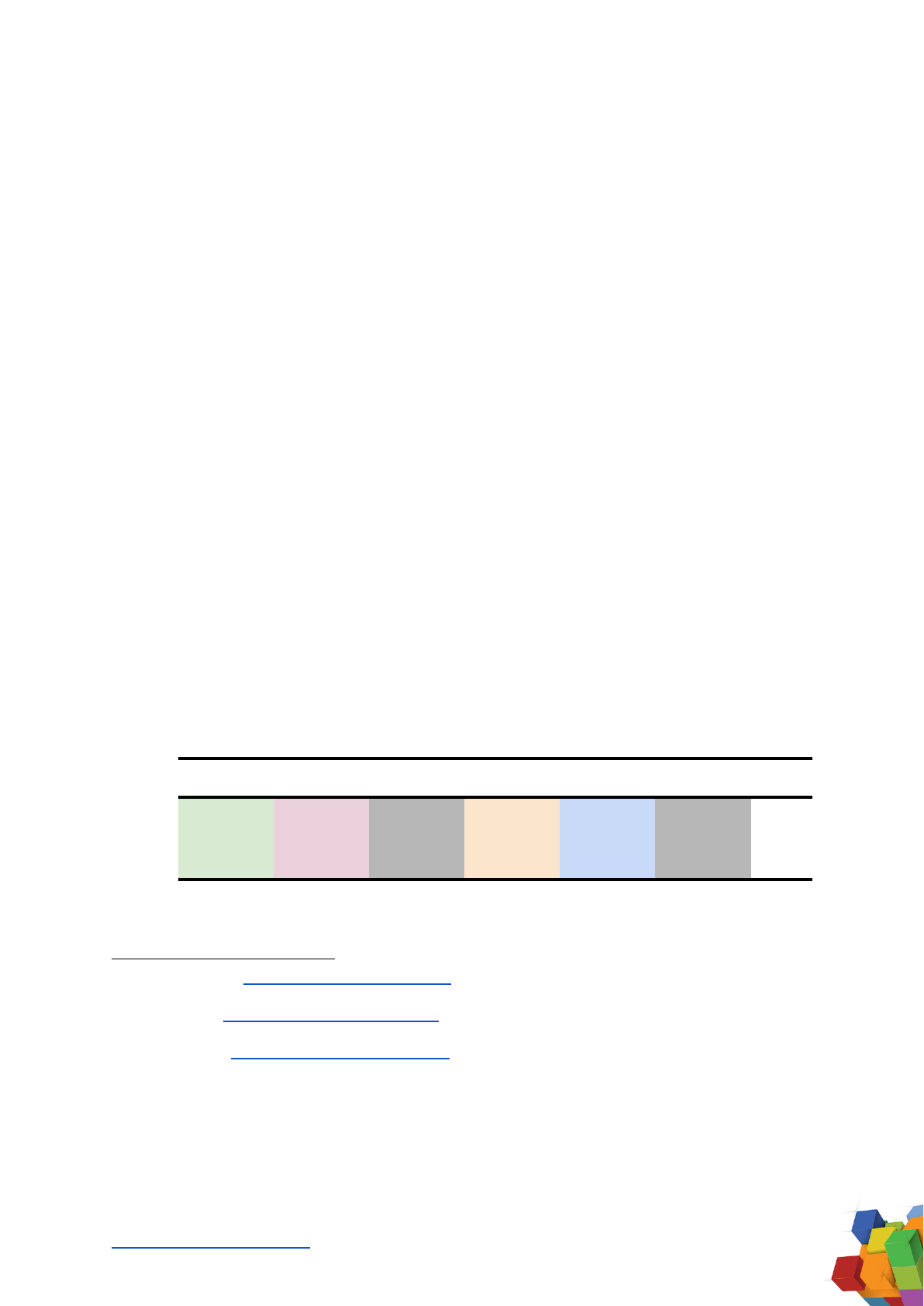
7. Megatron-11B & RoBERTa Datasets
The RoBERTa model was released by Meta AI (then Facebook AI) and the University
of Washington in 2019, with 125M parameters. The Megatron-11B model was released
by Meta AI (then Facebook AI) in 2020, with 11B parameters. It used the same training
dataset as RoBERTa. The RoBERTa
24
paper was clear about the contents of the
training datasets used, though cited papers (BERT
25
and Stories
26
) had to be
referenced to determine final sizes.
BookCorpus: determined to be 4.6GB, referenced as in the GPT-1 section above.
Wikipedia: disclosed as “BookCorpus plus English Wikipedia… 16GB.” Wikipedia was
determined to be 11.4GB after subtracting the BookCorpus (4.6GB, as referenced in
the GPT-1 section above).
CC-News: disclosed as 76GB after filtering.
OpenWebText: disclosed as 38GB.
Stories: disclosed as 31GB. Note that this dataset is Common Crawl content “based
on questions in commonsense reasoning tasks”, and does not fit into the ‘Books’
category in this article. Instead, it is combined with the CC-News dataset (76GB),
making a Common Crawl total of 107GB.
7.1. Megatron-11B & RoBERTa Dataset Summary
The final dataset summary analysis of the Megatron-11B and RoBERTa models is:
Wikipedia
Books
Journals
Reddit links
CC
Other
Total
GB
11.4
4.6
38
107
161
Tokens
3
1
15
143
162
Table 13. Megatron-11B & RoBERTa Datasets Summary. Disclosed in bold.
Determined in italics.
26
Stories paper: https://arxiv.org/abs/1806.02847 pp5-6: “Namely, we build a customized text corpus
based on questions in commonsense reasoning tasks. It is important to note that this does not include
the answers and therefore does not provide supervision to our resolvers. In particular, we aggregate
documents from the CommonCrawl dataset that has the most overlapping n-grams with the questions…
Documents in this corpus contain long series of events with complex references from several
pronouns. The top 0.1% of highest ranked documents is chosen as our new training corpus. We name
this dataset STORIES since most of the constituent documents take the form of a story with long chain
of coherent events.”
25
BERT paper: https://arxiv.org/abs/1810.04805 “BERT is trained on the BooksCorpus (800M words)
and Wikipedia (2,500M words).”
24
RoBERTa paper: https://arxiv.org/abs/1907.11692 “BOOKCORPUS plus English WIKIPEDIA. This is the
original data used to train BERT. (16GB).”
___________________
Alan D. Thompson. 2022. What’s in my AI? A Comprehensive Analysis of Datasets used to Train GPT…
https://LifeArchitect.ai/whats-in-my-ai 16

8. MT-NLG Datasets
The MT-NLG model was released by NVIDIA and Microsoft in 2021, with 530B
parameters. MT-NLG is the successor to Microsoft Turing NLG 17B and NVIDIA
Megatron-LM 8.3B. The MT-NLG paper was very clear about the sources and tokens
of the training datasets used, though sizes were not explicitly noted.
Further detail on sizes can be determined using information made available in The
Pile v1 paper, as covered earlier in this article. Despite using the same components, it
should be noted that reported component sizes in MT-NLG and The Pile v1 are
different, due to different filtering and deduplication methods employed by
researchers from Eleuther AI (The Pile v1 dataset) and Microsoft/NVIDIA (MT-NLG
model).
8.1. Common Crawl in MT-NLG
Pile-CC: disclosed as 49.8B tokens, determined to be around 227.12GB, referenced in
The Pile v1 section above.
CC-2020-50: disclosed as 68.7B tokens, assume a tokens per byte rate of 0.25 TpB =
274.8GB.
CC-2021-04: disclosed as 82.6B tokens, assume a tokens per byte rate of 0.25 TpB =
330.4GB
RealNews (from RoBERTa/Megatron-11B): disclosed as 21.9B tokens. Using the
RealNews paper
27
, the dataset is determined to be 120GB.
CC-Stories (from RoBERTa/Megatron-11B): disclosed as 5.3B tokens, determined to be
31GB as in RoBERTa section above.
Total Common Crawl data from all sources above is determined to be 983.32GB, with
228.3B tokens.
27
RealNews paper: https://arxiv.org/abs/1905.12616v3 “After deduplication, RealNews is 120 gigabytes
without compression.”
___________________
Alan D. Thompson. 2022. What’s in my AI? A Comprehensive Analysis of Datasets used to Train GPT…
https://LifeArchitect.ai/whats-in-my-ai 17

8.2. MT-NLG Grouped Datasets
Count
Dataset
Size from
Pile v1 (GB)
Pile Tokens
(see above)
▲
▼
MT-NLG
Tokens
1
2
Common Crawl (Pile-CC)
Other CC as above
227.12
756.2
52.0B
-
▼
49.8B
178.5B
Common Crawl total
983.3
228.3B
3
OpenWebText2
62.77
15.3B
▼
14.8B
4
Wikipedia
6.38
1.5B
▲
4.2B
5
6
7
Books
Books3
BookCorpus2
Gutenberg
100.96
6.30
10.88
25.0B
1.5B
2.9B
▲
-
▼
25.7B
1.5B
2.7B
Books total
118.14
29.4
29.9
8
9
10
Journals
PubMed Abstracts
NIH ExPorter
ArXiv
19.26
1.89
56.21
4.2B
0.4B
19.9B
▲
▼
▲
4.4B
0.3B
20.8B
Journals total
77.36
24.5
▲
25.5
11
12
Other
Stack Exchange
GitHub
32.20
95.16
11.1B
42.0B
▲
▼
11.6B
24.3B
Other total
127.36
53.1B
35.9
Total
1375.31
338.6B
Table 14. MT-NLG Grouped Datasets. Disclosed in bold. Determined in italics.
8.3. MT-NLG Dataset Summary
The final dataset summary analysis of the MT-NLG model is:
Wikipedia
Books
Journals
Reddit links
CC
Other
Total
GB
6.4
118.1
77.4
62.8
983.3
127.3
1375
Tokens
4.2
29.9
228.3
14.8
143
35.9
339
Table 15. MT-NLG Datasets Summary. Disclosed in bold. Determined in italics.
___________________
Alan D. Thompson. 2022. What’s in my AI? A Comprehensive Analysis of Datasets used to Train GPT…
https://LifeArchitect.ai/whats-in-my-ai 18

9. Gopher Datasets
The Gopher model was released by DeepMind in 2021, with 280B parameters. The
paper was clear about the high-level token counts and sizes
28
of the training dataset
used, but not about the detailed contents.
Count
Dataset
Raw Size (GB)
Tokens
1
2
3
4
5
6
MassiveWeb
Books
C4
News
GitHub
Wikipedia
1900
2100
750
2700
3100
1
506B
560B
182B
676B
422B
4B
Total
10551
2350B
Table 16. Disclosed Gopher Datasets (MassiveText). Disclosed in bold. Determined in
italics.
Of interest, the Gopher paper disclosed that its Books dataset contains some books
that are more than 500 years old (1500-2008).
9.1. MassiveWeb Dataset Analysis
DeepMind was acquired by Google in 2014, and has access to enormous amounts of
data in the creation of MassiveText. While the subset MassiveWeb is not detailed
much further in the Gopher paper, an Appendix on pp 44, Figure A3b notes the Top
20 domains appearing in MassiveWeb
29
. Given the disclosed percentage represented
for each domain, we can use the MassiveWeb total token count (506B tokens) and
total Raw Size (1900GB) to determine the token count and size of each domain.
Count
Domain
Percentage
tokens
Tokens
(PT x 506B)
Size
(PT x 1900GB)
1
2
3
4
5
6
7
8
9
ScienceDirect
Gale
NCBI
Facebook
Issuu
Academia
Quora
Springer
YouTube
1.85%
1.79%
1.59%
1.10%
0.98%
0.93%
0.75%
0.73%
0.73%
9.4B
9.1B
8.0B
5.6B
5.0B
4.7B
3.8B
3.7B
3.7B
35.2GB
34.0GB
30.2GB
20.9GB
18.6GB
17.7GB
14.3GB
13.9GB
13.9GB
29
Gopher paper: https://arxiv.org/abs/2112.11446 pp 44, Figure A3b.
28
Gopher paper: https://arxiv.org/abs/2112.11446 pp 7: list of sizes and tokens.
___________________
Alan D. Thompson. 2022. What’s in my AI? A Comprehensive Analysis of Datasets used to Train GPT…
https://LifeArchitect.ai/whats-in-my-ai 19

Count
Domain
Percentage
tokens
Tokens
(PT x 506B)
Size
(PT x 1900GB)
10
11
12
13
14
15
16
17
18
19
20
ProQuest Search
English Wikipedia
SlideShare
SlidePlayer
Reddit
Medium
Wiley Online Library
Europe PubMed Central
GitHub
DocPlayer
StackOverflow
0.68%
0.66%
0.58%
0.57%
0.51%
0.42%
0.38%
0.38%
0.33%
0.32%
0.28%
3.4B
3.3B
2.9B
2.9B
2.6B
2.1B
1.9B
1.9B
1.7B
1.6B
1.4B
12.9GB
12.5GB
11.0GB
10.8GB
9.7GB
8.0GB
7.2GB
7.2GB
6.3GB
6.1GB
5.3GB
Table 17. MassiveWeb: Top 20 Domains. Disclosed in bold. Determined in italics.
9.2. Gopher: Concerns with Dataset Analysis of Wikipedia
The total size of the Wikipedia dataset is challenging to determine. In the Gopher
paper, the researchers note that no deduplication is applied to Wikipedia
30
. However,
the disparate sizes listed in the paper (12.5GB MassiveWeb Wikipedia vs 1GB
MassiveText Wikipedia) may be due to an error, perhaps listing ‘1GB’ instead of ‘10GB’.
In any case, for this article, only the MassiveWeb dataset version (12.5GB) is used.
9.3. Gopher: No WebText
The WebText dataset of outbound Reddit links is not included as part of the Gopher
dataset. For clarity, while Reddit is a Top Domain in MassiveWeb, the dataset is only
capturing Reddit links within the Reddit domain. By definition, WebText
31
is comprised
of “ all outbound links from Reddit” (that is, links that lead to domains outside of the
Reddit domain).
31
GPT-2 paper, pp3.
30
Gopher paper: pp41n14 “Note that we apply document deduplication to all MassiveText subsets with
the exception of Wikipedia and GitHub.”
___________________
Alan D. Thompson. 2022. What’s in my AI? A Comprehensive Analysis of Datasets used to Train GPT…
https://LifeArchitect.ai/whats-in-my-ai 20

9.4. Gopher Grouped Datasets
MassiveWeb is considered as a sub-component of MassiveText, and integrated into
the dataset summary of Gopher, with grouping based on available information listed
below:
Count
Source
Domain
Tokens
(PT x 506B)
Size
(PT x 1900GB)
1
MassiveWeb
Wikipedia
3.3B
12.5GB
2
MassiveText
Books
560B
2100GB
3
4
5
6
7
8
9
10
11
MassiveWeb
MassiveWeb
MassiveWeb
MassiveWeb
MassiveWeb
MassiveWeb
MassiveWeb
MassiveWeb
MassiveWeb
ScienceDirect
Gale
NCBI
Academia
Springer
ProQuest Search
Wiley Online Library
Europe PubMed Central
DocPlayer
9.4B
9.1B
8.0B
4.7B
3.7B
3.4B
1.9B
1.9B
1.6B
35.2GB
34.0GB
30.2GB
17.7GB
13.9GB
12.9GB
7.2GB
7.2GB
6.1GB
Journals total
41.8B
164.4
12
13
MassiveText
MassiveText
C4
News
182B
676B
750GB
2700GB
Common Crawl Total
858B
3450GB
14
15
MassiveText
MassiveWeb
GitHub
Remainder:
(Size: 1900 - 12.5 - 164.4)
(Tokens: 506B - 3.3 - 41.8)
422B
460.9B
3100GB
1723.1GB
Other total
882.9B
4823.1
Total
2346B
10550GB
Table 18. Gopher Grouped Datasets. Disclosed in bold. Determined in italics.
___________________
Alan D. Thompson. 2022. What’s in my AI? A Comprehensive Analysis of Datasets used to Train GPT…
https://LifeArchitect.ai/whats-in-my-ai 21
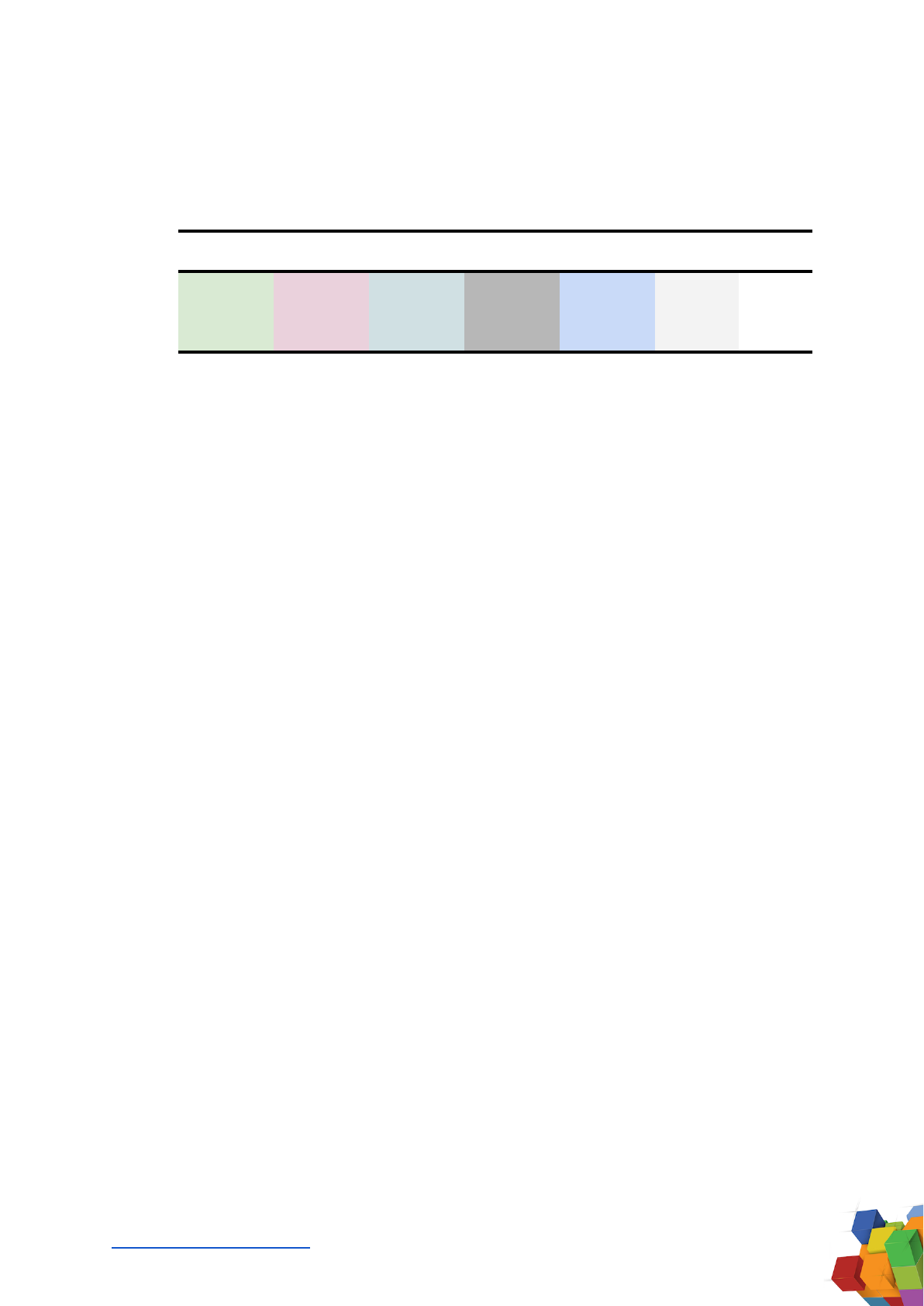
9.5. Gopher Dataset Summary
Gopher features the largest dataset in this article, at 10.5TB. The final dataset
summary analysis of the Gopher model is:
Wikipedia
Books
Journals
Reddit links
CC
Other
Total
GB
12.5
2100
164.4
3450
4823
10550
Tokens
3
560
42
858
883
2346
Table 19. Gopher Datasets Summary. Disclosed in bold. Determined in italics.
10. Conclusion
We present possibly the most comprehensive synthesis and analysis of datasets used
to train modern transformer large language models to early 2022. Where primary
sources were opaque, the research synthesized here was collected from secondary
and tertiary sources, and often necessitated assumptions to determine final estimates.
As researchers approach quadrillions of tokens (1,000 trillion), and petabytes of data
(1,000TB), it is becoming increasingly important to ensure that the documentation of
dataset composition is disclosed in detail.
Of particular concern is the rapid progress of verbose and anonymous output from
powerful AI systems based on large language models, many of which have little
documentation of dataset details.
Researchers are strongly encouraged to employ templates provided in the ‘Datasheet
for Datasets’ paper highlighted, and to use best-practice papers (i.e. The Pile v1 paper,
with token count) when documenting datasets. Metrics for dataset size (GB), token
count (B), source, grouping, and other details should be fully documented and
published.
As language models continue to evolve and penetrate all human lives more fully, it is
useful, urgent, and necessary to ensure that dataset details are accessible,
transparent, and understandable for all.
___________________
Alan D. Thompson. 2022. What’s in my AI? A Comprehensive Analysis of Datasets used to Train GPT…
https://LifeArchitect.ai/whats-in-my-ai 22

11. Further reading
For brevity and readability, footnotes were used in this article, rather than
in-text/parenthetical citations. Primary reference papers are listed below, or please
see http://lifearchitect.ai/papers/ for the major foundational papers in the large
language model space. Papers below are shown in order of appearance in this
article.
Datasheets for Datasets
Gebru, T., Morgenstern, J., Vecchione, B., Vaughan, J., Wallach, H., Daumé III, H., &
Crawford, K. (2018). Datasheets for Datasets. https://arxiv.org/abs/1803.09010
GPT-1 paper
Radford, A., & Narasimhan, K. (2018). Improving Language Understanding by
Generative Pre-Training. OpenAI.
https://cdn.openai.com/research-covers/language-unsupervised/language_understan
ding_paper.pdf
GPT-2 paper
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D. & Sutskever, I. (2019). Language
Models are Unsupervised Multitask Learners. OpenAI.
https://cdn.openai.com/better-language-models/language_models_are_unsupervised
_multitask_learners.pdf
GPT-3 paper
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., & Dhariwal, P. et al. (2020).
OpenAI. Language Models are Few-Shot Learners. https://arxiv.org/abs/2005.14165
The Pile v1 paper
Gao, L., Biderman, S., Black, S., Golding, L., Hoppe, T., & Foster, C. et al. (2021). The
Pile: An 800GB Dataset of Diverse Text for Language Modeling. EleutherAI.
https://arxiv.org/abs/2101.00027
GPT-J announcement
Komatsuzak, A., Wang, B. (2021). GPT-J-6B: 6B JAX-Based Transformer.
https://arankomatsuzaki.wordpress.com/2021/06/04/gpt-j/
GPT-NeoX-20B paper
Black, S., Biderman, S., Hallahan, E. et al. (2022). EleutherAI. GPT-NeoX-20B: An
Open-Source Autoregressive Language Model.
http://eaidata.bmk.sh/data/GPT_NeoX_20B.pdf
RoBERTa paper
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., & Chen, D. et al. (2019). RoBERTa: A Robustly
Optimized BERT Pretraining Approach. Meta AI. https://arxiv.org/abs/1907.11692
___________________
Alan D. Thompson. 2022. What’s in my AI? A Comprehensive Analysis of Datasets used to Train GPT…
https://LifeArchitect.ai/whats-in-my-ai 23

MT-NLG paper
Smith, S., Patwary, M., Norick, B., LeGresley, P., Rajbhandari, S., & Casper, J. et al.
(2021). Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A
Large-Scale Generative Language Model. Microsoft/NVIDIA.
https://arxiv.org/abs/2201.11990
Gopher paper
Rae, J., Borgeaud, S., Cai, T., Millican, K., Hoffmann, J., & Song, F. et al. (2021). Scaling
Language Models: Methods, Analysis & Insights from Training Gopher. DeepMind.
https://arxiv.org/abs/2112.11446
___________________
Alan D. Thompson. 2022. What’s in my AI? A Comprehensive Analysis of Datasets used to Train GPT…
https://LifeArchitect.ai/whats-in-my-ai 24

Appendix A: Top 50 Resources: Wikipedia + CC + WebText (i.e. GPT-3)
Based on determinations made in this article, especially token counts per resource in
each dataset, we can show the rankings of top resources or domains for models
which use a combination of Wikipedia + Common Crawl + WebText datasets as part of
their overall training dataset. For clarity, this includes the following models: OpenAI
GPT-3, EleutherAI GPT-J, EleutherAI GPT-NeoX-20B, Meta AI Megatron-11B and
RoBERTA, and Microsoft/NVIDIA MT-NLG, and others.
Note that the ranking shown is based on unweighted total tokens available within
datasets, and subjective weightings per dataset are calculated by researchers prior to
model pre-training. Some duplication appears (e.g. The New York Times appears in
both WebText at 111M tokens and filtered Common Crawl at 100M tokens).
Rank
Resource/Domain
Dataset Group
Tokens (M)
Unweighted
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
Biography
Google Patents
Geography
Google
Culture and Arts
History
Biology, Health, and Medicine
Archive
Sports
Blogspot
Business
GitHub
Other society
The NY Times
WordPress
Science & Math
WashingtonPost
Wikia
BBC
The NY Times
Los Angeles Times
The Guardian
PLoS
TheGuardian
Forbes
HuffingtonPost
Patents.com
Scribd
eBay
Wikipedia
Common Crawl
Wikipedia
WebText
Wikipedia
Wikipedia
Wikipedia
WebText
Wikipedia
WebText
Wikipedia
WebText
Wikipedia
WebText
WebText
Wikipedia
WebText
WebText
WebText
Common Crawl
Common Crawl
Common Crawl
Common Crawl
WebText
Common Crawl
Common Crawl
Common Crawl
Common Crawl
WebText
834
750
531
514
474
297
234
199
195
152
144
138
132
111
107
105
105
104
104
100
90
90
90
82
80
75
71
70
70
___________________
Alan D. Thompson. 2022. What’s in my AI? A Comprehensive Analysis of Datasets used to Train GPT…
https://LifeArchitect.ai/whats-in-my-ai 25

Rank
Resource/Domain
Dataset Group
Tokens (M)
Unweighted
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
Pastebin
CNN
Washington Post
Yahoo
HuffingtonPost
Go
The Motley Fool
Reuters
IMDb
IPFS
Frontiers Media
Business Insider
Chicago Tribune
Booking.com
The Atlantic
Springer Link
Al Jazeera
Kickstarter
Goo
FindLaw Caselaw
NCBI
WebText
WebText
Common Crawl
WebText
WebText
WebText
Common Crawl
WebText
WebText
Common Crawl
Common Crawl
Common Crawl
Common Crawl
Common Crawl
Common Crawl
Common Crawl
Common Crawl
Common Crawl
WebText
Common Crawl
Common Crawl
70
66
65
65
62
62
61
61
61
60
60
60
59
58
57
56
55
54
54
53
53
Total
7300M
(7.3B)
___________________
Alan D. Thompson. 2022. What’s in my AI? A Comprehensive Analysis of Datasets used to Train GPT…
https://LifeArchitect.ai/whats-in-my-ai 26
